如何在Ubuntu18和Centos7下搭建Hadoop2.6.5集群和伪集群

Hadoop被公认是一套行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。单节点集群是利用一台主机模拟Hadoop运行环境,可以使用Hadoop所有模块

一、准备
1.1创建Hadoop用户
在操作过程中,ubuntu系统和centos系统不同的执行的命令我都做了说明,没有说明的命令则两种系统都能执行
ubuntu命令
sudo useradd -m hadoop -s /bin/bash # 创建hadoop用户,并使用/bin/bash作为shell |
centos命令
sudo useradd -m hadoop -s /bin/bash # 创建hadoop用户,并使用/bin/bash作为shell |
1.2设置SSH无密码登录
ubuntu命令
sudo apt-get install openssh-server # 安装SSH server |
centos命令
rpm -qa | grep ssh # 查看ssh是否安装,如果包含了SSH client跟SSH server,则不需要再安装 |
二、安装JDK
ubuntu命令
java -version # 查看当前java版本,未出现版本信息代表未安装 |
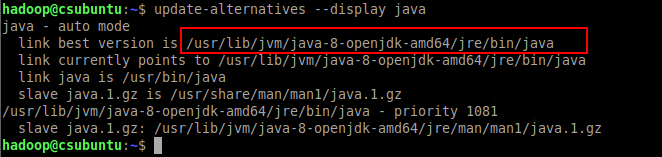
查询java安装路径路径,记住该路径,下面步骤中的配置要用到
update-alternatives --display java |
centos命令 安装openJDK
yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel.x86_64 |
jdk路径
/usr/lib/jvm/java-1.8.0-openjdk |
三、下载安装Hadoop
ubuntu命令
apt-get install wget |
centos命令
yum -y install wget |
下载安装hadoop
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.6.4/hadoop-2.6.5.tar.gz # 下载hadoop |
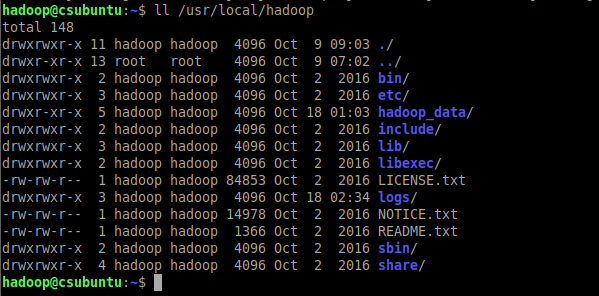
- bin是运行文件目录,包括Hadoop、HDFS和YARN
- sbin是shell文件目录,包括start-all.sh、stop-all.sh
- etc/hadoop目录包含hadoop配置文件
- lib是hadoop函数库目录
- logs系统日志目录
四、设置Hadoop环境变量
在终端输入命令打开编辑器
使用vim编辑器,点击键盘"i", 就能开始编辑。输入配置文件内容后,点击键盘"esc"键,然后输入:wq来保存退出
ubuntu命令
sudo vim --version # 检查是否安装vim |
centos命令
sudo rpm -qa|grep vim # 检查是否安装vim |
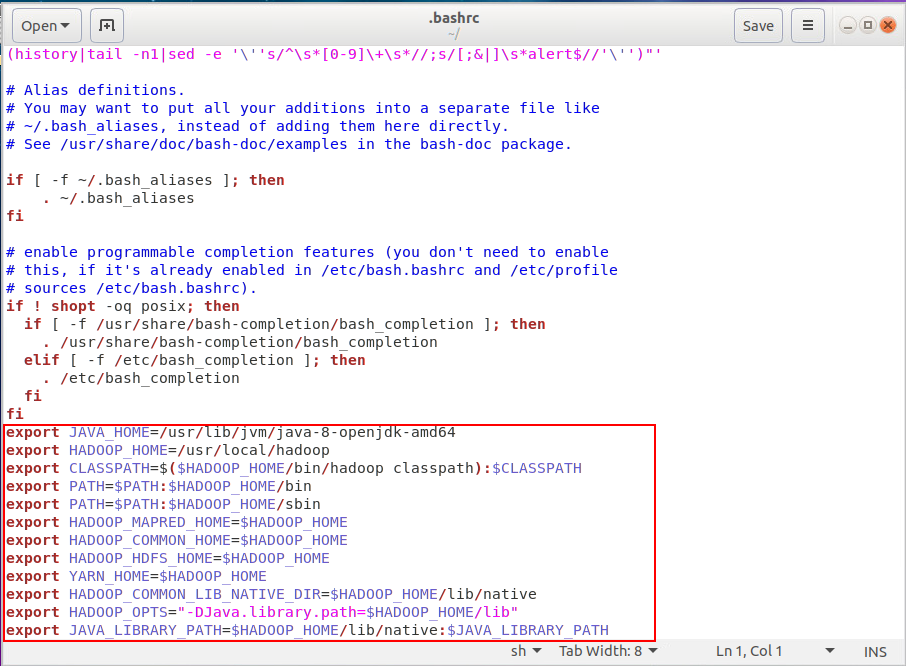
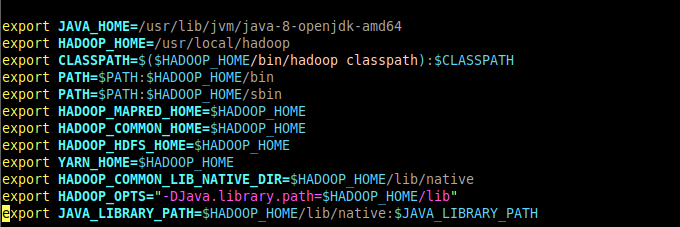
在编辑器中输入下面内容
# 设置jdk安装路径,参考安装jdk的部分输出的路径 |
或者图形界面可以使用sudo gedit ~/.bashrc命令编辑,在编辑器中输入后,然后按ctrl+s保存,再关闭编辑器
让设置立即生效
source ~/.bashrc |
五、修改Hadoop配置文件
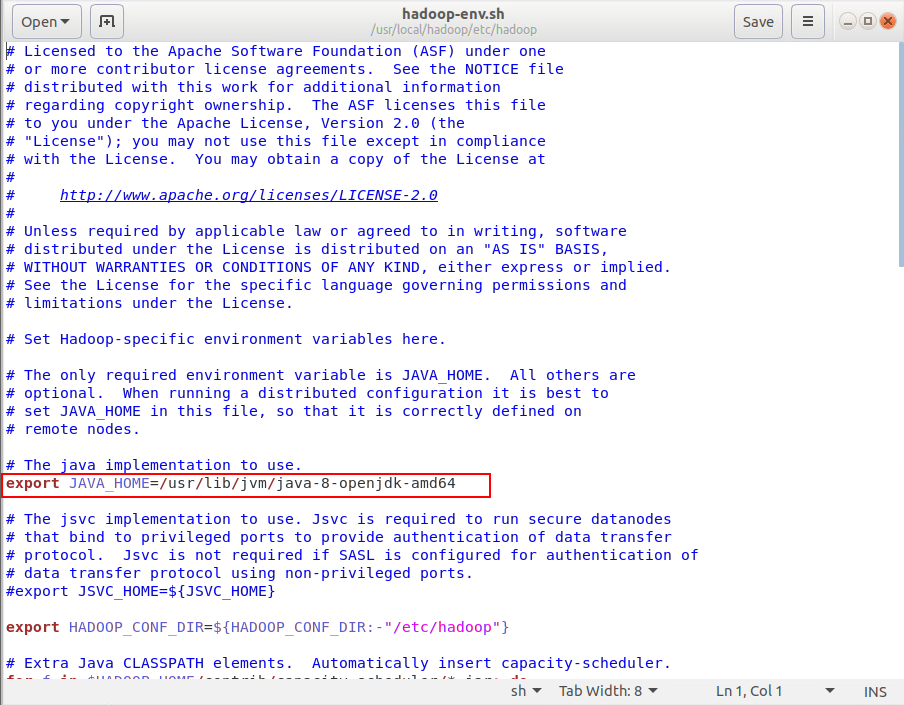
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh |
设置JAVA_HOME的路径,参考安装jdk的部分输出的路径,编辑完成保存退出
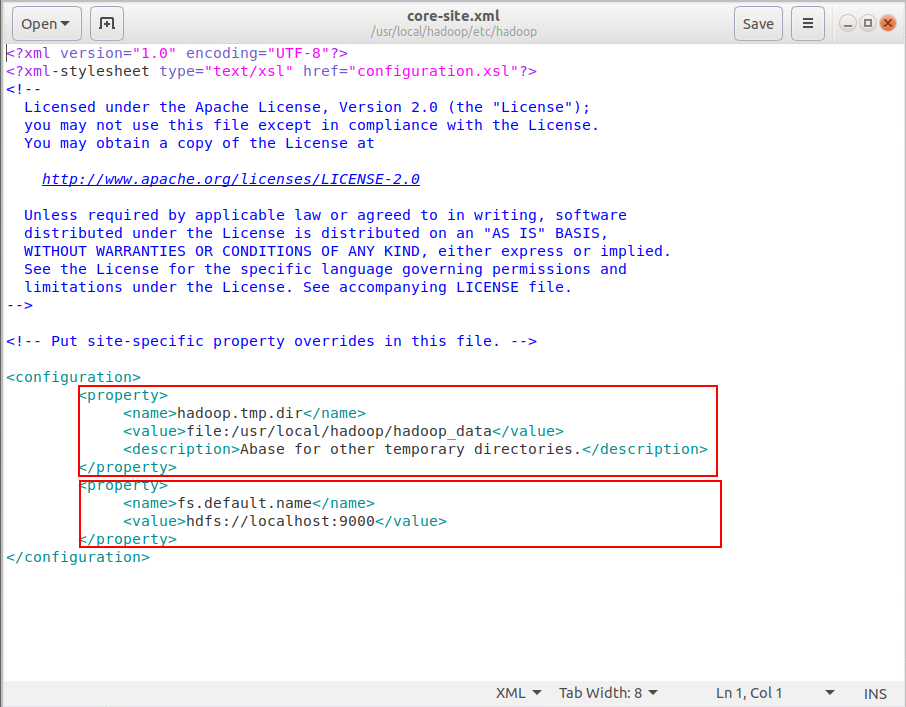
修改core-site.xml文件
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml |
输入以下内容
<configuration> |
第一个节点是临时目录,第二个节点是HDFS默认名称
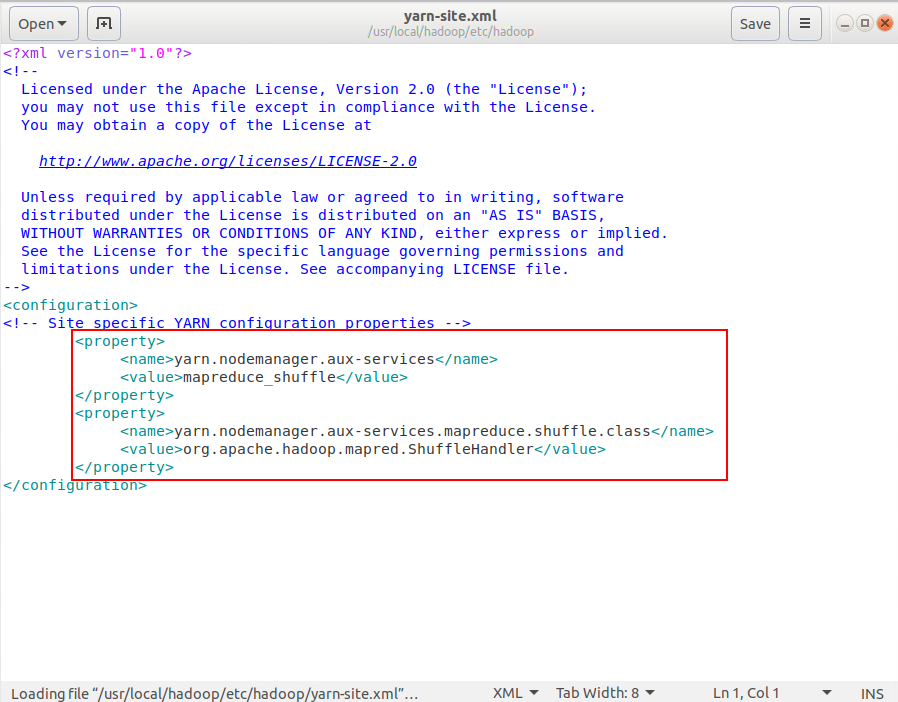
编辑yarn-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml |
输入以下内容
<configuration> |
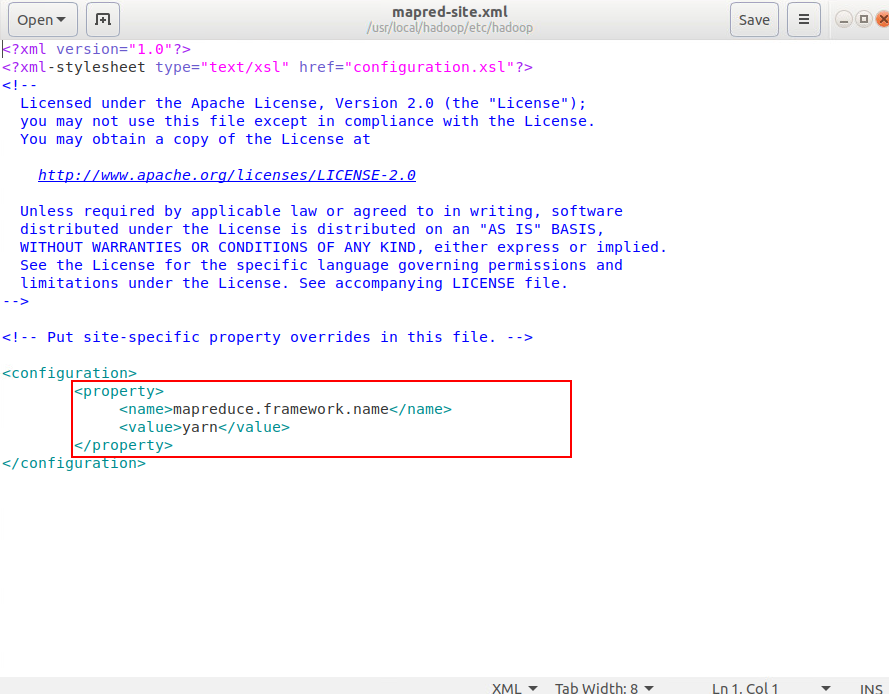
编辑mapred-site.xml,mapred-site.xml用于监控Map与Reduce程序的JobTracker任务分配情况以及TaskTracker任务运行情况
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml #复制模板文件 |
输入以下内容
<configuration> |
这个节点是设置mapreduce框架为yarn
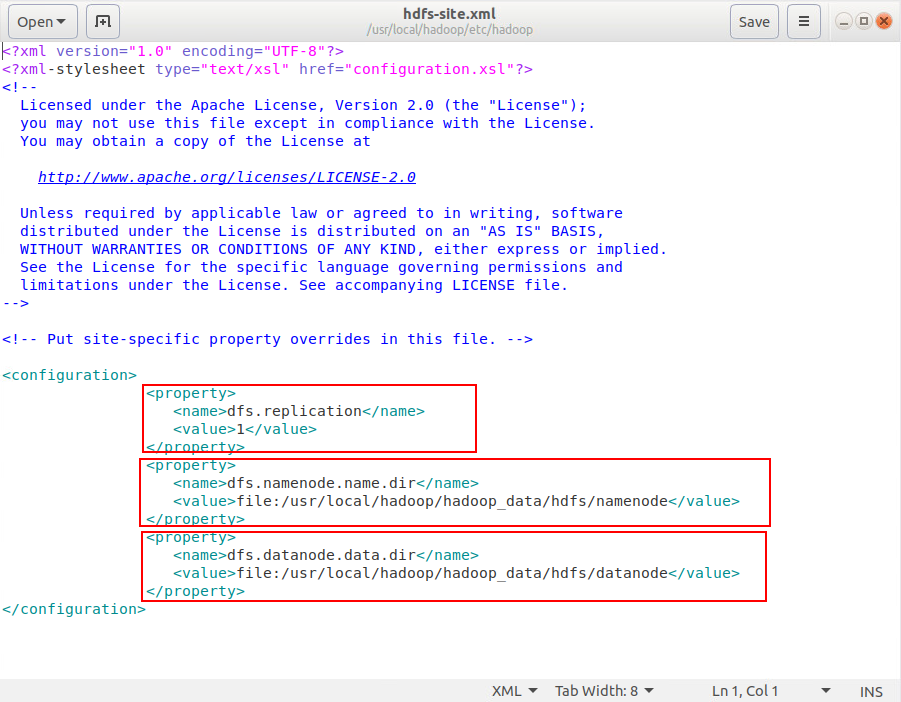
编辑 hdfs-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml |
输入下面内容
<configuration> |
第一个节点是设置blocks副本备份数量,第二个是NameNode数据存储目录,第三个是DataNode数据存储目录
六、创建并格式化HDFS目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode #创建namenode数据存储目录 |
七、启动Hadoop
start-dfs.sh #启动HDFS |
或者同时启动
start-all.sh |
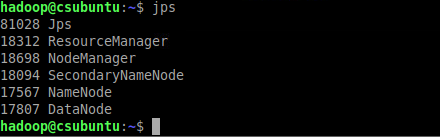
输入jps查看进程是否启动
查看Hadoop ResourceManager Web页面,打开浏览器输入 http://localhost:8088/

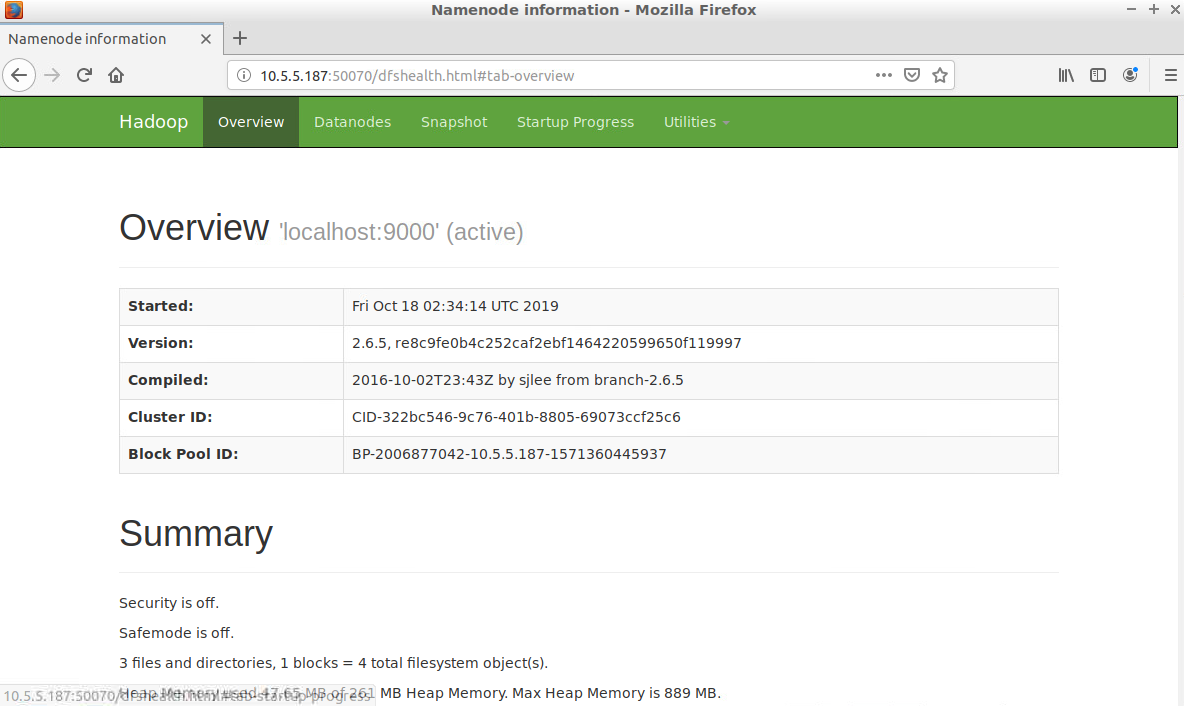
查看NameNode HDFS Web页面,打开浏览器输入 http://localhost:50070/
八、搭建hadoop集群
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回分布式模式,需要修改配置文件,先按照上面一二三四步骤搭建环境,再进行下面的步骤
准备四台计算机,其中有一台namenode和三台datanode
8.1 配置第一台datanode服务器
先把ip改成固定ip
ubuntu改ip命令
sudo vim /etc/network/interfaces #改ip, |
centos改ip命令
vim /etc/sysconfig/network-scripts/ifcfg-ens192 #改ip, |
修改主机名为data1
sudo vim /etc/hostname |
编辑hosts文件,每台ip对应一个主机
sudo vim /etc/hosts |
编辑core-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml |
输入以下内容
<configuration> |
编辑yarn-site.xml
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml |
输入下面内容
<configuration> |
以上设置说明:
- ResourceManager主机与NodeManager的连接地址为8025
- ResourceManager与ApplicationMater的连接地址为8030
- ResourceManager与客户端的连接地址为8050
编辑mapred-site.xml
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml |
输入下面内容
<configuration> |
编辑hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml |
输入下面内容,设置datanode目录
<configuration> |
重复以上步骤再建立3台主机,如果是VM虚拟机则复制3台虚拟机
8.2 配置第二台datanode服务器
先把ip改成固定ip
ubuntu改ip命令
sudo vim /etc/network/interfaces #改ip, |
centos改ip命令
vim /etc/sysconfig/network-scripts/ifcfg-ens192 #改ip, |
改主机名为data2
sudo vim /etc/hostname |
8.3 配置第三台datanode服务器
先把ip改成固定ip
ubuntu改ip命令
sudo vim /etc/network/interfaces #改ip, |
centos改ip命令
vim /etc/sysconfig/network-scripts/ifcfg-ens192 #改ip, |
改主机名为data3
sudo vim /etc/hostname |
8.4 配置一台namenode服务器
先把ip改成固定ip
ubuntu改ip命令
sudo vim /etc/network/interfaces #改ip, |
centos改ip命令
vim /etc/sysconfig/network-scripts/ifcfg-ens192 #改ip, |
改主机名为master
sudo vim /etc/hostname |
编辑hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml |
输入下面内容,设置datanode目录
<configuration> |
编辑masters文件,主要是告诉hadoop哪一台服务器是namenode
sudo vim /usr/local/hadoop/etc/hadoop/masters # 设置master |
编辑slaves文件,主要是告诉hadoop哪一台服务器是datanode
sudo vim /usr/local/hadoop/etc/hadoop/slaves #设置data1,data2,data3 |
手动重启所有服务器
8.5 mater连接data1、data2、data3,创建HDFS目录
使用master主机连接data1进行配置
ssh data1 # ssh连接到data1 |
使用master主机连接data2进行配置
ssh data2 # ssh连接到data1 |
使用master主机连接data3进行配置
ssh data3 # ssh连接到data1 |
创建并格式化namenode HDFS目录
su - hadoop # 切换hadoop用户 |
8.6 启动集群
start-dfs.sh # 启动HDFS,第一次会询问,输入yes |
或者同时启动
start-all.sh |
如果要停止可以用
stop-all.sh |
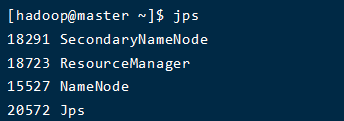
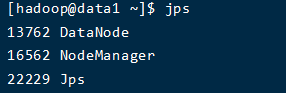
查看master启动的进程
jsp |
查看data1启动的进程
ssh data1 # ssh连接data1 |
8.7 端口开放说明
集群启动后由于存在防火墙,所以hadoop无法访问,可以按需开放以下端口。或者直接关闭,一劳永逸
| 组件 | 节点 | 默认端口 | 配置 | 用途说明 |
|---|---|---|---|---|
| HDFS | DataNode | 50010 | dfs.datanode.address | datanode服务端口,用于数据传输 |
| HDFS | DataNode | 50075 | dfs.datanode.http.address | http服务的端口 |
| HDFS | DataNode | 50475 | dfs.datanode.https.address | https服务的端口 |
| HDFS | DataNode | 50020 | dfs.datanode.ipc.address | ipc服务的端口 |
| HDFS | NameNode | 50070 | dfs.namenode.http-address | http服务的端口 |
| HDFS | NameNode | 50470 | dfs.namenode.https-address | https服务的端口 |
| HDFS | NameNode | 8020 | fs.defaultFS | 接收Client连接的RPC端口,用于获取文件系统metadata信息。 |
| HDFS | journalnode | 8485 | dfs.journalnode.rpc-address | RPC服务 |
| HDFS | journalnode | 8480 | dfs.journalnode.http-address | HTTP服务 |
| HDFS | ZKFC | 8019 | dfs.ha.zkfc.port | ZooKeeper FailoverController,用于NN HA |
| YARN | ResourceManager | 8032 | yarn.resourcemanager.address | RM的applications manager(ASM)端口 |
| YARN | ResourceManager | 8030 | yarn.resourcemanager.scheduler.address | scheduler组件的IPC端口 |
| YARN | ResourceManager | 8031 | yarn.resourcemanager.resource-tracker.address | IPC |
| YARN | ResourceManager | 8033 | yarn.resourcemanager.admin.address | IPC |
| YARN | ResourceManager | 8088 | yarn.resourcemanager.webapp.address | http服务端口 |
| YARN | NodeManager | 8040 | yarn.nodemanager.localizer.address | localizer IPC |
| YARN | NodeManager | 8042 | yarn.nodemanager.webapp.address | http服务端口 |
| YARN | NodeManager | 8041 | yarn.nodemanager.address | NM中container manager的端口 |
| YARN | JobHistory Server | 10020 | mapreduce.jobhistory.address | IPC |
| YARN | JobHistory Server | 19888 | mapreduce.jobhistory.webapp.address | http服务端口 |
| HBase | Master | 60000 | hbase.master.port | IPC |
| HBase | Master | 60010 | hbase.master.info.port | http服务端口 |
| HBase | RegionServer | 60020 | hbase.regionserver.port | IPC |
| HBase | RegionServer | 60030 | hbase.regionserver.info.port | http服务端口 |
| HBase | HQuorumPeer | 2181 | hbase.zookeeper.property.clientPort | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase | HQuorumPeer | 2888 | hbase.zookeeper.peerport | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase | HQuorumPeer | 3888 | hbase.zookeeper.leaderport | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| Hive | Metastore | 9083 | /etc/default/hive-metastore中export PORT= |
|
| Hive | HiveServer | 10000 | /etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT= |
|
| ZooKeeper | Server | 2181 | /etc/zookeeper/conf/zoo.cfg中clientPort= |
对客户端提供服务的端口 |
| ZooKeeper | Server | 2888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | follower用来连接到leader,只在leader上监听该端口。 |
| ZooKeeper | Server | 3888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | 用于leader选举的。只在electionAlg是1,2或3(默认)时需要。 |
例如开放8025端口
sudo firewall-cmd --zone=public --permanent --add-port=8025/tcp |
其他防火墙命令
sudo firewall-cmd --state # 运行状态 |
九、Hadoop常用的HDFS命令
| 命令 | 说明 |
|---|---|
| hadoop fs -mkdir | 创建HDFS目录 |
| hadoop fs -ls | 列出HDFS目录 |
| hadoop fs -copyFromLocal | 使用copyFromLocal复制本地文件到HDFS |
| hadoop fs -put | 使用put复制本地文件到HDFS |
| hadoop fs -cat | 列出HDFS目录下的文件内容 |
| hadoop fs -copyToLocal | 使用copyToLocal将HDFS上的文件复制到本地 |
| hadoop fs -cp | 复制HDFS文件 |
| hadoop fs -rm | 删除HDFS文件 |
操作示例
hadoop fs -mkdir -p /usr/hadoop/test # 创建/usr/hadoop/test目录 |
十、遇到的问题和解决办法
在安装完成后发现namenode进程没有启动,打不开 http://localhost:50070/ 页面。首先去查看日志
cd /usr/local/hadoop/logs #进入日志目录 |
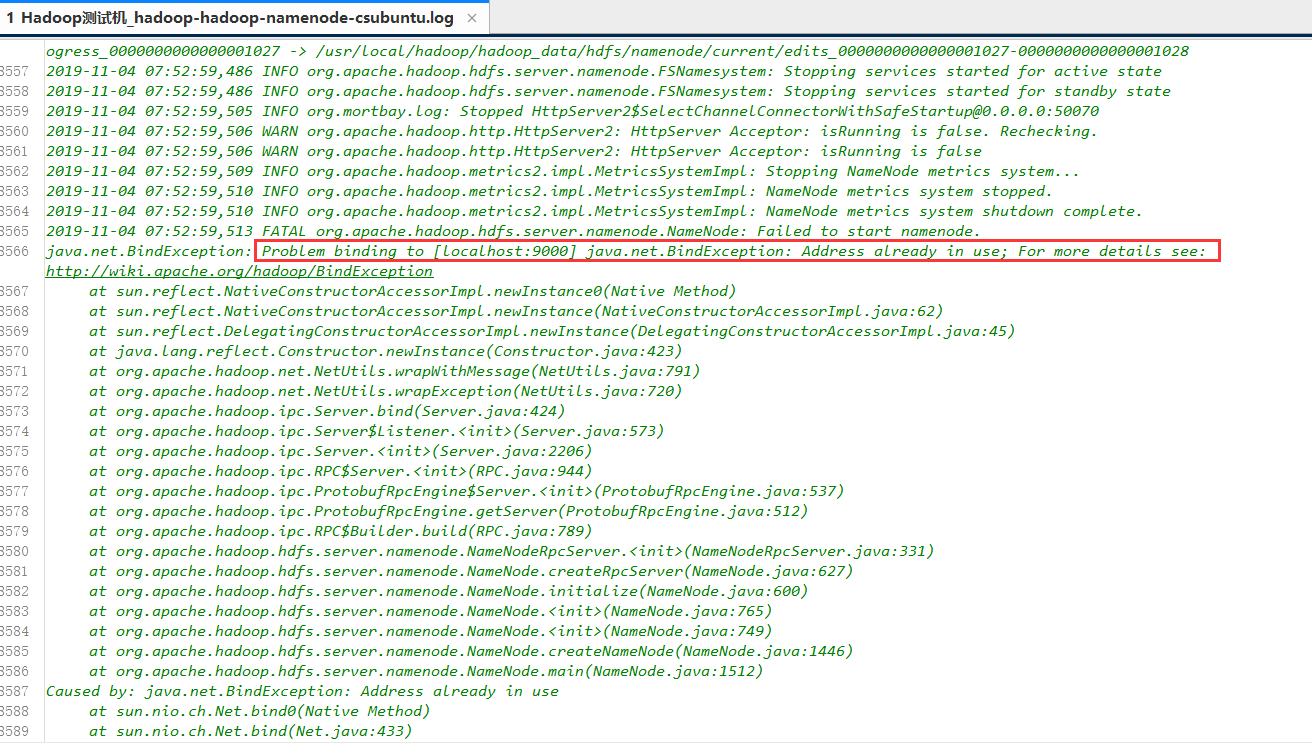
发现是9000端口被占用
sudo netstat -lnp | grep 9000 #查看9000端口占用 |

看到是nginx占用了9000端口,把nginx停止就能重新启动hadoop
ps -ef | grep nginx #查看nginx主进程 |

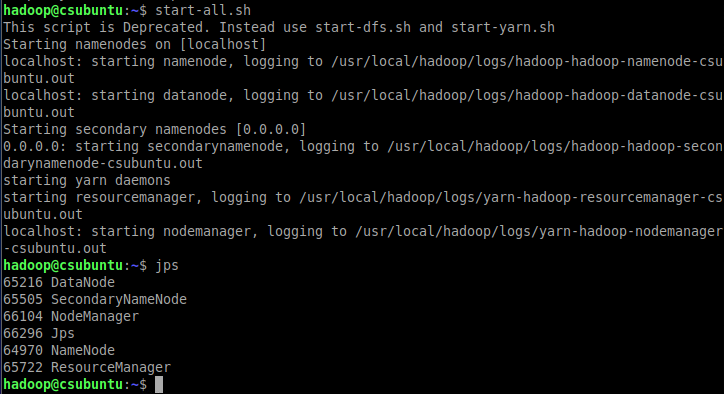
启动hadoop守护进程
 如何使用Ubuntu18安装Hivehive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表并提供类sql查询功能
如何使用Ubuntu18安装Hivehive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表并提供类sql查询功能 使用Ubuntu19.10搭建一个编程工作站如何配置ubuntu在个人工作站与服务器领域都表现的非常稳定优秀,工程师使用ubuntu做为个人开发电脑完全没有问题,功能齐全性能...在Ubuntu16.04使用命令行方式安MatlabLinux服务器命令行模式安装Matlab
使用Ubuntu19.10搭建一个编程工作站如何配置ubuntu在个人工作站与服务器领域都表现的非常稳定优秀,工程师使用ubuntu做为个人开发电脑完全没有问题,功能齐全性能...在Ubuntu16.04使用命令行方式安MatlabLinux服务器命令行模式安装Matlab 如何使用Ubuntu16.04挂载硬盘操作前先要添加一块硬盘
查看硬盘位置
sudo fdisk -l
根据磁盘大小,我挂的是40g的,所以很明显是 /dev...Linux出现Read-onlyFileSystem错误的解决方法造成这个问题的原因大多数是因为非正常关机后导致文件系统受损引起的,在系统重启之后,
受损分区就会被Linux自动挂载为只读...
如何使用Ubuntu16.04挂载硬盘操作前先要添加一块硬盘
查看硬盘位置
sudo fdisk -l
根据磁盘大小,我挂的是40g的,所以很明显是 /dev...Linux出现Read-onlyFileSystem错误的解决方法造成这个问题的原因大多数是因为非正常关机后导致文件系统受损引起的,在系统重启之后,
受损分区就会被Linux自动挂载为只读...博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议