你应该知道的Python3各个版本的新特性

 最近在使用python过程中,看到了一段提示文本。发现python3.5的使用寿命已于2020年9月13日结束,pip 21.0也将于2021年1月删除对Python 3.5的支持。导致很多第三方模块要求python的最低标准是python3.6。
最近在使用python过程中,看到了一段提示文本。发现python3.5的使用寿命已于2020年9月13日结束,pip 21.0也将于2021年1月删除对Python 3.5的支持。导致很多第三方模块要求python的最低标准是python3.6。
现在是时候升级你的python了,学习新版本python特性有助于提高对python的了解。
一、Python3.6新的语法特性
1、格式化字符串(Formatted string literals)
即在普通字符串前添加 f 或 F 前缀,其效果类似于str.format()。比如
name = "Fred" |
其效果相当于:
print("He said his name is {name}.".format(**locals())) |
此外,此特性还支持嵌套字段,比如:
width = 10 |
2、变量声明语法(variable annotations)
即从Python3.5开始就有的Typehints。在Python3.5中,是这么使用的:
from typing import List |
这里的语法检查只在编辑器(比如Pycharm)中产生,在实际的使用中,并不进行严格检查。 在Python3.6中,引入了新的语法:
from typing import List, Dict |
3、数字的下划线写法(Underscores in Numeric Literals)
即允许在数字中使用下划线,以提高多位数字的可读性。
a = 1_000_000_000_000_000 # 1000000000000000 |
除此之外,“字符串格式化”也支持“_”选项,以打印出更易读的数字字符串:
'{:_}'.format(1000000) # '1_000_000' |
4、异步生成器(Asynchronous Generators)
在Python3.5中,引入了新的语法 async 和 await 来实现协同程序。但是有个限制,不能在同一个函数体内同时使用 yield 和 await,在Python3.6中,这个限制被放开了,Python3.6中允许定义异步生成器:
async def ticker(delay, to): |
5、异步解析器(Asynchronous Comprehensions)
即允许在列表list、集合set 和字典dict 解析器中使用 async for 或 await 语法。
result = [i async for i in aiter() if i % 2] |
6、新增标准模块
Python标准库(The Standard Library)中增加了一个新的模块:secrets。该模块用来生成一些安全性更高的随机数,以用来管理数据,比如passwords, account authentication, security tokens, 以及related secrets等。具体用法可参考官方文档:secrets
7、其他新特性
- 新的 PYTHONMALLOC 环境变量允许开发者设置内存分配器,以及注册debug钩子等。
- asyncio模块更加稳定、高效,并且不再是临时模块,其中的API也都是稳定版的了。
- typing模块也有了一定改进,并且不再是临时模块。
- datetime.strftime 和 date.strftime 开始支持ISO 8601的时间标识符%G, %u, %V。
- hashlib 和 ssl 模块开始支持OpenSSL1.1.0。
- hashlib模块开始支持新的hash算法,比如BLAKE2, SHA-3 和 SHAKE。
- Windows上的 filesystem 和 console 默认编码改为UTF-8。
- json模块中的 json.load() 和 json.loads() 函数开始支持 binary 类型输入。
- .......
更多新功能,参考官方文档:https://docs.python.org/3/whatsnew/3.6.html
二、Python3.7 新特性
Python 3.7 于 2018 年 6 月 27 日发布, 包含许多新特性和优化,增添了众多新的类,可用于数据处理、针对脚本编译和垃圾收集的优化以及更快的异步 I/O,主要如下:
- 用类处理数据时减少样板代码的数据类。
- 一处可能无法向后兼容的变更涉及处理生成器中的异常。
- 面向解释器的 “开发模式”。
- 具有纳秒分辨率的时间对象。
- 环境中默认使用 UTF-8 编码的 UTF-8 模式。
- 触发调试器的一个新的内置函数。
1、新增内置函数 breakpoint()
使用该内置函数,相当于通过代码的方式设置了断点,会自动进入 Pbd 调试模式。
如果在环境变量中设置 PYTHONBREAKPOINT=0 会忽略此函数。并且,pdb 只是众多可用调试器之一,你可以通过设置新的 PYTHONBREAKPOINT 环境变量来配置想要使用的调试器。
下面有一个简单例子,用户需要输入一个数字,判断它是否和目标数字一样:
def guess(target): |
不幸的是,即使猜的数和目标数一样,打印的结果也是‘猜错了',并且没有任何异常或错误信息。
为了弄清楚发生了什么,我们可以插入一个断点,来调试一下。以往一般通过 print 大法或者 IDE 的调试工具,但现在我们可以使用 breakpoint()。
def guess(target): |
在 pdb 提示符下,我们可以调用 locals() 来查看当前的本地作用域的所有变量。(pdb 有大量的命令,你也可以在其中运行正常的 Python 语句)
请输入你猜的数 >>> 100 |
搞明白了,target 是一个整数,而 user_guess 是一个字符串,这里发生了类型对比错误。
2、类型和注解
从 Python 3.5 开始,类型注解就越来越受欢迎。对于那些不熟悉类型提示的人来说,这是一种完全可选的注释代码的方式,以指定变量的类型。
什么是注解?它们是关联元数据与变量的语法支持,可以是任意表达式,在运行时被 Python 计算但被忽略。注解可以是任何有效的 Python 表达式。
下面是个对比的例子:
def foo(bar, baz): |
上面的做法,其实是 Python 对自身弱类型语言的强化,希望获得一定的类型可靠和健壮度,向 Java 等语言靠拢。
在 Python 3.5 中,注解的语法获得标准化,此后,Python 社区广泛使用了注解类型提示。
但是,注解仅仅是一种开发工具,可以使用 PyCharm 等 IDE 或 Mypy 等第三方工具进行检查,并不是语法层面的限制。
我们前面的猜数程序如果添加类型注解,它应该是这样的:
def guess(target:str): |
PyCharm 会给我们灰色的规范错误提醒,但不会给红色的语法错误提示。
用注解作为类型提示时,有两个主要问题:启动性能和前向引用。
- 在定义时计算大量任意表达式相当影响启动性能,而且 typing 模块非常慢
- 你不能用尚未声明的类型来注解
typing 模块如此缓慢的部分原因是,最初的设计目标是在不修改核心 CPython 解释器的情况下实现 typing 模块。随着类型提示变得越来越流行,这一限制已经被移除,这意味着现在有了对 typing 的核心支持。
而对于向前引用,看下面的例子:
class User: |
错误在于 User 类型还没有被声明,此时的 prev_user 不能定义为 User 类型。
为了解决这个问题,Python3.7 将注解的评估进行了推迟。并且,这项改动向后不兼容,需要先导入 annotations,只有到 Python 4.0 后才会成为默认行为。
from __future__ import annotations |
或者如下面的例子:
class C: |
3、新增 dataclasses 模块
这个特性可能是 Python3.7 以后比较常用的,它有什么作用呢?
假如我们需要编写一个下面的类:
from datetime import datetime |
大量的初始化属性要定义默认值,可能还需要重写一堆魔法方法,来实现类实例的打印、比较、排序和去重等功能。 如果使用 dataclasses 进行改造,可以写成这个样子:
from dataclasses import dataclass, field |
这使得类不仅容易设置,而且当我们创建一个实例并打印出来时,它还可以自动生成优美的字符串。在与其他类实例进行比较时,它也会有适当的行为。这是因为 dataclasses 除了帮我们自动生成 init 方法外,还生成了一些其他特殊方法,如 repr、eq 和 hash 等。
Dataclasses 使用字段 field 来完提供默认值,手动构造一个 field() 函数能够访问其他选项,从而更改默认值。例如,这里将 field 中的 default_factory 设置为一个 lambda 函数,该函数提示用户输入其名称。
from dataclasses import dataclass, field |
4、生成器异常处理
在 Python 3.7 中,生成器引发 StopIteration 异常后,StopIteration 异常将被转换成 RuntimeError 异常,那样它不会悄悄一路影响应用程序的堆栈框架。这意味着如何处理生成器的行为方面不太敏锐的一些程序会在 Python 3.7 中抛出 RuntimeError。在 Python 3.6 中,这种行为生成一个弃用警告;在 Python 3.7 中,它将生成一个完整的错误。
一个简易的方法是使用 try/except 代码段,在 StopIteration 传播到生成器的外面捕获它。更好的解决方案是重新考虑如何构建生成器――比如说,使用 return 语句来终止生成器,而不是手动引发 StopIteration。
5、开发模式
Python 解释器添加了一个新的命令行开关:-X,让开发人员可以为解释器设置许多低级选项。
这种运行时的检查机制通常对性能有重大影响,但在调试过程中对开发人员很有用。
-X 激活的选项包括:
- asyncio 模块的调试模式。这为异步操作提供了更详细的日志记录和异常处理,而异常操作可能很难调试或推理。
- 面向内存分配器的调试钩子。这对于编写 CPython 扩展件的那些人很有用。它能够实现更明确的运行时检查,了解 CPython 如何在内部分配内存和释放内存。
- 启用 faulthandler 模块,那样发生崩溃后,traceback 始终转储出去。
6、 高精度时间函数
Python 3.7 中一类新的时间函数返回纳秒精度的时间值。尽管 Python 是一种解释型语言,但是 Python 的核心开发人员维克多 • 斯廷纳(Victor Stinner)主张报告纳秒精度的时间。最主要的原因是,在处理转换其他程序(比如数据库)记录的时间值时,可以避免丢失精度。
新的时间函数使用后缀_ns。比如说,time.process_time() 的纳秒版本是 time.process_time_ns()。请注意,并非所有的时间函数都有对应的纳秒版本。
7、其他新特性
- 字典现在保持插入顺序。这在 3.6 中是非正式的,但现在成为了官方语言规范。在大多数情况下,普通的 dict 能够替换 collections.OrderedDict。
- .pyc 文件具有确定性,支持可重复构建 —— 也就是说,总是为相同的输入文件生成相同的 byte-for-byte 输出。
- 新增 contextvars 模块,针对异步任务提供上下文变量。
- __main__中的代码会显示弃用警告(DeprecationWarning)。
- 新增 UTF-8 模式。在 Linux/Unix 系统,将忽略系统的 locale,使用 UTF-8 作为默认编码。在非 Linux/Unix 系统,需要使用 - X utf8 选项启用 UTF-8 模式。
- 允许模块定义__getattr__、__dir__函数,为弃用警告、延迟 import 子模块等提供便利。
- 新的线程本地存储 C 语言 API。
- 更新 Unicode 数据到 11.0。
三、Python3.8 新特性
Python3.8 版本于 2019 年 10 月 14 日发布,以下是 Python 3.8 相比 3.7 的新增特性。
1、海象赋值表达式
新的语法 :=,将值赋给一个更大的表达式中的变量。它被亲切地称为 “海象运算符”(walrus operator),因为它长得像海象的眼睛和象牙。
“海象运算符” 在某些时候可以让你的代码更整洁,比如:
在下面的示例中,赋值表达式可以避免调用 len () 两次:
if (n := len(a)) > 10: |
类似的好处还可体现在正则表达式匹配中需要使用两次匹配对象的情况中,一次检测用于匹配是否发生,另一次用于提取子分组:
discount = 0.0 |
此运算符也可用于配合 while 循环计算一个值,来检测循环是否终止,而同一个值又在循环体中再次被使用的情况:
while (block := f.read(256)) != '': |
或者出现于列表推导式中,在筛选条件中计算一个值,而同一个值又在表达式中需要被使用:
[clean_name.title() for name in names |
请尽量将海象运算符的使用限制在清晰的场合中,以降低复杂性并提升可读性。
2、仅限位置形参
新增一个函数形参语法 / 用来指明某些函数形参必须使用仅限位置而非关键字参数的形式。
这种标记语法与通过 help () 所显示的使用 Larry Hastings 的 Argument Clinic 工具标记的 C 函数相同。
在下面的例子中,形参 a 和 b 为仅限位置形参,c 或 d 可以是位置形参或关键字形参,而 e 或 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f): |
以下是合法的调用:
f(10, 20, 30, d=40, e=50, f=60) |
但是,以下均为不合法的调用:
f(10, b=20, c=30, d=40, e=50, f=60) |
这种标记形式的一个用例是它允许纯 Python 函数完整模拟现有的用 C 代码编写的函数的行为。例如,内置的 pow () 函数不接受关键字参数:
def pow(x, y, z=None, /): |
另一个用例是在不需要形参名称时排除关键字参数。例如,内置的 len () 函数的签名为 len (obj, /)。这可以排除如下这种笨拙的调用形式:
另一个益处是将形参标记为仅限位置形参将允许在未来修改形参名而不会破坏客户的代码。例如,在 statistics 模块中,形参名 dist 在未来可能被修改。这使得以下函数描述成为可能:
def quantiles(dist, /, *, n=4, method='exclusive') |
由于在 / 左侧的形参不会被公开为可用关键字,其他形参名仍可在 **kwargs 中使用:
def f(a, b, /, **kwargs): |
这极大地简化了需要接受任意关键字参数的函数和方法的实现。例如,下面是 collections 模块中的代码摘录:
class Counter(dict): |
3、f 字符串支持
增加 = 说明符用于 f-string。形式为 f'{expr=}' 的 f 字符串将扩展表示为表达式文本,加一个等于号,再加表达式的求值结果。例如:
user = 'eric_idle' |
4、typing 模块的改进
Python 是动态类型语言,但可以通过 typing 模块添加类型提示,以便第三方工具验证 Python 代码。Python 3.8 给 typing 添加了一些新元素,因此它能够支持更健壮的检查:
- final 修饰器和 Final 类型标注表明,被修饰或被标注的对象在任何时候都不应该被重写、继承,也不能被重新赋值。
- Literal 类型将表达式限定为特定的值或值的列表(不一定是同一个类型的值)。
- TypedDict 可以用来创建字典,其特定键的值被限制在一个或多个类型上。注意这些限制仅用于编译时确定值的合法性,而不能在运行时进行限制。
5、多进程共享内存
multiprocessing 模块新增 SharedMemory 类,可以在不同的 Python 进城之间创建共享的内存区域。
在旧版本的 Python 中,进程间共享数据只能通过写入文件、通过网络套接字发送,或采用 Python 的 pickle 模块进行序列化等方式。共享内存提供了进程间传递数据的更快的方式,从而使得 Python 的多处理器和多内核编程更有效率。
共享内存片段可以作为单纯的字节区域来分配,也可以作为不可修改的类似于列表的对象来分配,其中能保存数字类型、字符串、字节对象、None 对象等一小部分 Python 对象。
6、新版本的 pickle 协议
Python 的 pickle 模块提供了一种序列化和反序列化 Python 数据结构或实例的方法,可以将字典原样保存下来供以后读取。不同版本的 Python 支持的 pickle 协议不同,而 3.8 版本的支持范围更广、更强大、更有效的序列化。
Python 3.8 引入的第 5 版 pickle 协议可以用一种新方法 pickle 对象,它能支持 Python 的缓冲区协议,如 bytes、memoryviews 或 Numpy array 等。新的 pickle 避免了许多在 pickle 这些对象时的内存复制操作。
NumPy、Apache Arrow 等外部库在各自的 Python 绑定中支持新的 pickle 协议。新的 pickle 也可以作为 Python 3.6 和 3.7 的插件使用,可以从 PyPI 上安装。
7、性能改进
- 许多内置方法和函数的速度都提高了 20%~50%,因为之前许多函数都需要进行不必要的参数转换。
- 一个新的 opcode 缓存可以提高解释器中特定指令的速度。但是,目前实现了速度改进的只有 LOAD_GLOBAL opcode,其速度提高了 40%。以后的版本中也会进行类似的优化。
- 文件复制操作如 shutil.copyfile() 和 shutil.copytree() 现在使用平台特定的调用和其他优化措施,来提高操作速度。
- 新创建的列表现在平均比以前小了 12%,这要归功于列表构造函数如果能提前知道列表长度的情况下,可以进行优化。
- Python 3.8 中向新型类(如 class A(object))的类变量中的写入操作变得更快。operator.itemgetter() 和 collections.namedtuple() 也得到了速度优化。
更多详细特性,请查阅 Python 3.8.0 文档:https://docs.python.org/zh-cn/3.8/whatsnew/3.8.html
四、Python3.9新特性
Python3.9 的一些新特性,如:更快速的进程释放,性能的提升,简便的新字符串函数,字典并集运算符以及更兼容稳定的内部 API,详细如下:
- 字典并集和可迭代更新
- 字符串方法
- 类型提示
- 新的数学函数
- 新的解析器
- IPv6 范围内的地址
- 新模块:区域信息
- 其他语言更改
1、字典并集和可迭代更新
Python 3.9 dict 类。如果有两个字典 a 和 b,则现在可以使用这些运算符进行合并和更新。
我们有合并运算符 |:

使用 Iterables 进行字典更新
| = 运算符的另一个很棒的性能是能够使用可迭代对象(如列表或生成器)用新的键值对来更新字典:
a = {'a': 'one', 'b': 'two'} |
2、字符串方法
removeprefix()和 removesuffix()
str.removeprefix(substring:string)字符串方法:如果 str 以它开头的话,将会返回一个修改过前缀的新字符串,否则它将返回原始字符串。
str.removesuffix(substring:string)字符串方法:如果 str 以其结尾,则返回带有修改过后缀的新字符串,否则它将返回原始字符串。

这两个函数执行的操作将使用 string [len(prefix):] 作为前缀,string [:-len(suffix)] 作为后缀。
这些是非常简单的操作,因此实现的也是非常简单的功能,但是考虑到可能会经常执行这些操作,最好有一个内置的函数可以完成此操作。
3、类型提示
Python 是动态类型的,动态地为变量指定数据类型,意味着我们无需在代码中指定数据类型。 但有时可能会造成混淆!
对于数据类型的静态分配,通常使用类型提示。这是在 Python 3.5 中引入的。从 3.5 开始,我们可以指定类型,但这是比较麻烦的。
这项更新真正改变了这一点,现在可以将内置集合类型(List 和 Dict)用作泛型类型。 之前,必须通过输入来调用大写类型 List 和 Dict。
ef greet_all(names: list[str]) -> None: |
现在,无需从 typing.List 来调用 List
4、新的数学函数
数学模块添加和改进了许多辅助功能,从对现有功能的改进开始。
以前计算最大公因数的 gcd 函数只能应用于 2 个数字,迫使程序员在处理更多数字时必须执行类似 math.gcd(80,math.gcd(64,152))的操作。从 Python 3.9 开始,我们可以将其应用于任意数字的值。
math 模块中第一个新添加的是 math.lcm 函数:
math.lcm 计算其参数的最小公倍数。与 GCD 一样,它允许可变数量的参数。
5、新的解析器
这部分更多是视线之外的改变,但有可能成为 Python 未来发展中最重大的改变之一。
Python 3.9 使用了一个新的基于 PEG 的解析器。以前 Python 使用 LL(1),在构建该语言的新功能时,PEG 比 LL(1)更灵活。官方文档中表示,这种灵活性将在 Python 3.10 及更高版本中体现出来。
ast 模块使用新的解析器,并产生与旧解析器相同的 AST。
6、IPv6 范围内的地址
Python 3.9 的另一个变化是可以指定 IPv6 地址的范围。IPv6 范围用于指定相应 IP 地址在 Internet 的哪个部分有效。
范围可以使用%符号在 IP 地址的末尾指定——例如:3FFE:0:0:1:200:F8FF:FE75:50DF%2——因此该 IP 地址在范围 2 中,即链接本地地址。
因此,如果需要使用 Python 处理 IPv6 地址,现在可以这样处理:
from ipaddress import IPv6Address |
7、新模块:区域信息
区域信息
zoneinfo 模块将 IANA 时区数据库的支持引入标准库。它添加了 zoneinfo.ZoneInfo,这是一个由系统时区数据支持的具体的 datetime.tzinfo 实现。
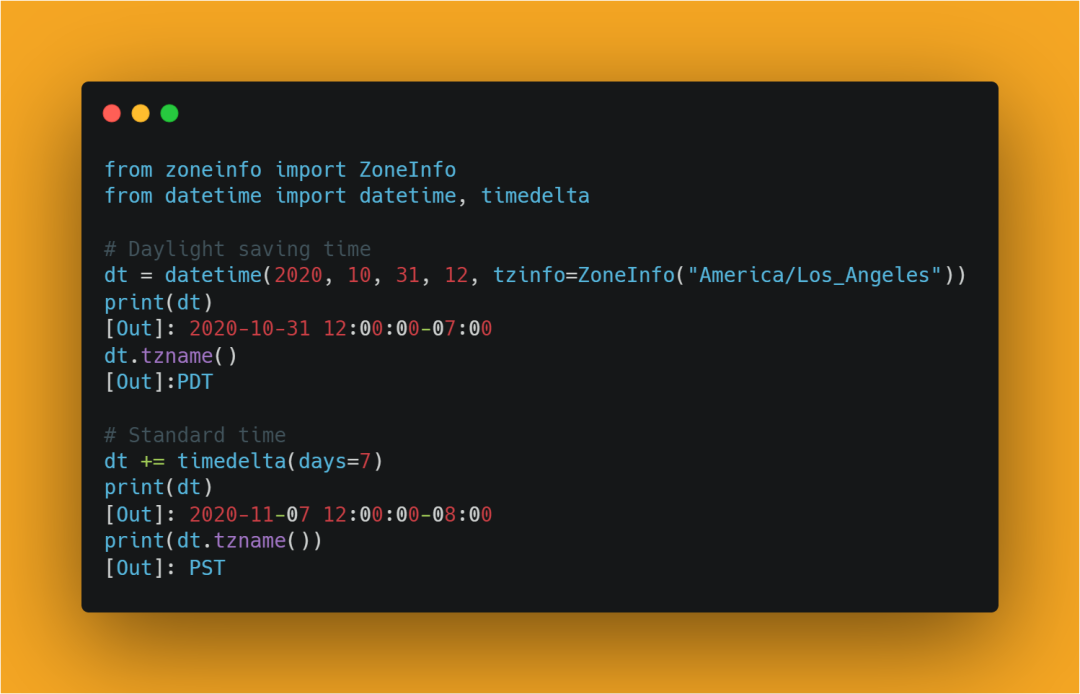
8、其他语言更改
__import __()现在增加了 ImportError 以替代 ValueError,通常在相对导入超出其顶级包时发生。 “” .replace(“”,s,n)现在对于所有非零 n 返回 s 而不是空字符串。现在它与 ““ .replace(”“,s)相一致。
默认状态下,Python 变得更快
Python 的每个修订版与以前的版本相比都有性能改进。Python 3.9 进行了两项重大改进,可以提高性能但无需对现有代码进行任何更改。
第一个改进更多涉及矢量调用协议的使用,通过最小化或消除临时对象进行许多常见函数的调用。Python 3.9 引入了几个新的内置函数,包括 range、tuple、set、frozenset、list、dict ——使用 vectorcall 可以加快执行速度。
Python 切换到年度发布周期
到目前为止,Python 已经以 18 个月的节奏进行了开发和发布。PEP 602 提议 Python 开发团队采用年度发布周期,并且该提议已被接受。
 Python包管理工具pip的使用pip是Python包管理工具,该工具提供了对Python包的查找、下载、安装、卸载的功能。Python模块psutil库的使用psutil (python system and process utilities) 是一个跨平台的第三方库,能够轻松...Python虚拟环境pipenv的常用命令Pipenv可以用于简化Python项目中依赖项的管理。只用了一年, Pipenv 就变成了管理软件包依赖关系的 Pyth...Python虚拟环境venv的使用
Python包管理工具pip的使用pip是Python包管理工具,该工具提供了对Python包的查找、下载、安装、卸载的功能。Python模块psutil库的使用psutil (python system and process utilities) 是一个跨平台的第三方库,能够轻松...Python虚拟环境pipenv的常用命令Pipenv可以用于简化Python项目中依赖项的管理。只用了一年, Pipenv 就变成了管理软件包依赖关系的 Pyth...Python虚拟环境venv的使用 使用Python将图片转字符画使用Pillow可以把图片转成字符画,Pillow是Python平台上的图像处理库,功能强大,简单易用。
使用Python将图片转字符画使用Pillow可以把图片转成字符画,Pillow是Python平台上的图像处理库,功能强大,简单易用。
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议